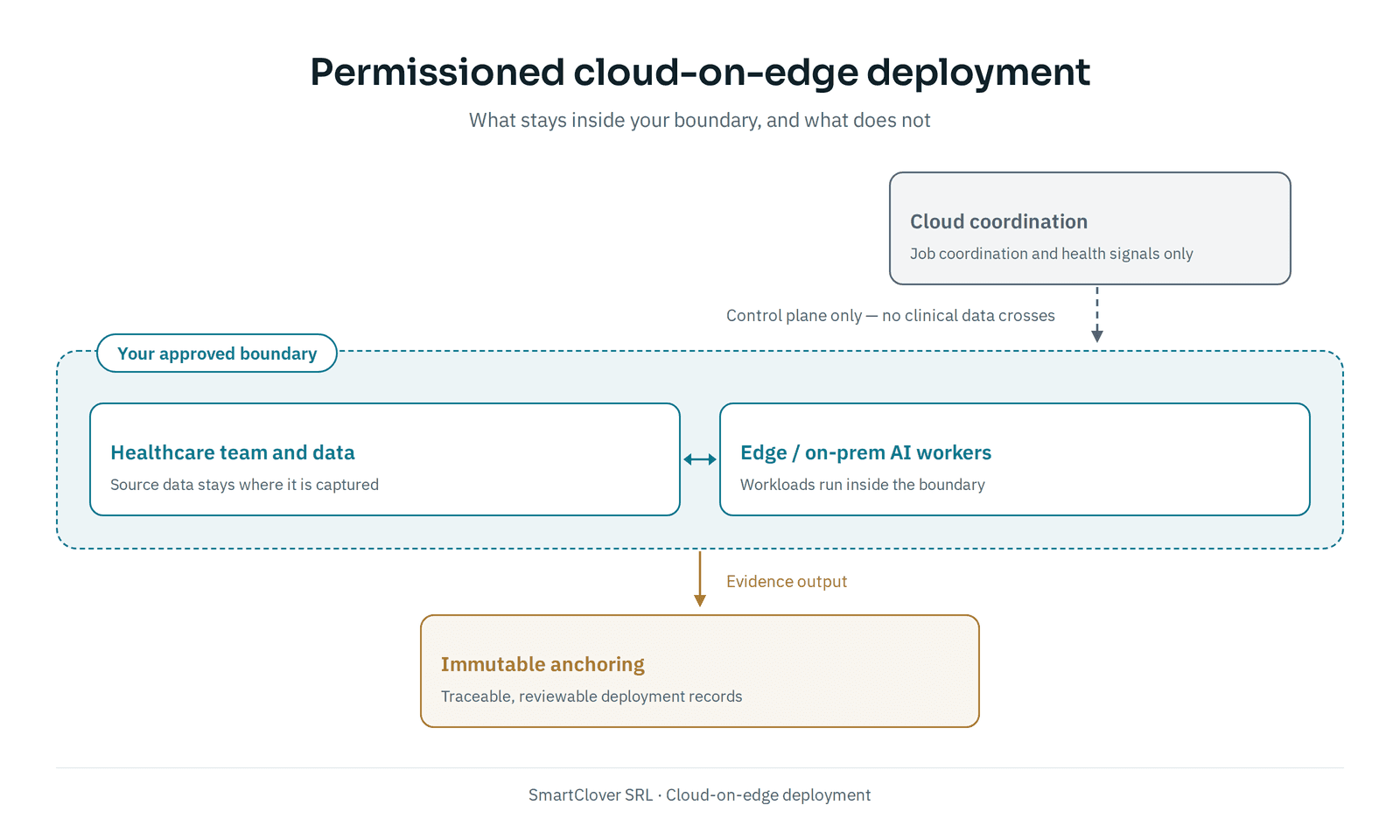
SmartClover uses permissioned cloud-on-edge deployment patterns for healthcare AI workloads that need clear data boundaries. Source-driven deployment can clone a repository, install dependencies, build the project, and launch it on permissioned edge/on-prem workers while cloud coordination supports release control, observability, and operational review.
For SmartClover, that means CerviGuard-related services, analytics portals, and security review workflows can run close to the teams that use them. Updates remain source-controlled, while orchestration, tunnels, observability, immutable anchoring, and traceable deployment records give technical and security reviewers a concrete release history to inspect.
The architecture is useful because it separates questions that often get blurred: where the workload runs, what data crosses boundaries, which controls protect sensitive flows, who can approve a release, and what evidence is retained.
In supported deployment models, sensitive flows can be end-to-end encrypted, clinical payload data is not centralized by default, and release events can be anchored for later audit and security review. Those controls still have to be scoped before production activation.
SmartClover therefore scopes regulated-sector requirements before deployment: tenant boundaries, encryption controls, release approvals, rollback expectations, evidence exports, and operational responsibility. Compliance fit is deployment-specific and depends on the contract, environment, local governance, and operating procedures.
The practical aim is to keep clinical payload data within approved boundaries, avoid unnecessary centralization, and make release history reviewable without turning architecture claims into universal compliance promises. Related public context is available on Cloud Architecture, Decentralized Deployment, and the Security baseline.
Last reviewed: 2026-05-11.